
Overview
该实验的任务是从电脑里选取较大的文件(大于10MB),给出从文件目录出发,查找该文件簇链信息的过程,并输出该文件的簇段,可以选区的filesystem有三种: FAT32, NTFS, ext3/ext4
Linux下的查找方式
我们先从Linux下的文件系统入手,因为是开源的,相对也要简单些
ext4基本知识
ext4 是Linux系统中最常用的文件系统之一,是 ext2/3 的改进版,它的性能、可靠性和容量支持上都有显著提升。其核心思想是通过inode、block、extent等结构管理文件数据
文件系统的基本单位:Block(块)
- 块(block) 是 ext4 文件系统分配磁盘空间的最小单位,常见大小为 4KB。
- 每个文件的数据都存放在一个或多个块中。
- 文件系统的性能、碎片率与块大小密切相关:块越大,寻址越少但浪费空间越多;块越小则反之。
文件元数据:Inode(索引节点)
每个文件对应一个 inode,其中保存文件的元数据信息:
- 文件类型(普通文件、目录、符号链接等)
- 访问权限与所有者
- 文件大小、时间戳(ctime、mtime、atime)
- 文件数据块(block)或 extent 的指针
注意:inode 本身不存储文件名,文件名保存在目录项(directory entry)中,通过 inode 号关联。
文件数据定位:Extent(区段)
ext4 相比 ext2/ext3 的最大改进之一是引入了 extent(簇段)结构。
- Extent 表示一个“连续的数据块范围”,形式为:
(逻辑块号范围) → (物理块号起点) - 一个文件通常包含多个 extent,每个 extent 描述一个连续的存储区域。
- 这种方式显著减少了文件碎片,提高了大文件访问效率。
目录(Directory)
- 目录也是一种文件,其内容是一系列 目录项(directory entries)。
- 每个目录项记录一个文件名与对应的 inode 号。
- 当用户通过路径访问文件时,系统会逐级查找目录项,直到找到目标 inode。
确定目标文件与文件系统类型
首先我们要确定我们计算机的文件系统类型,Linux一般为ext类型的
df -T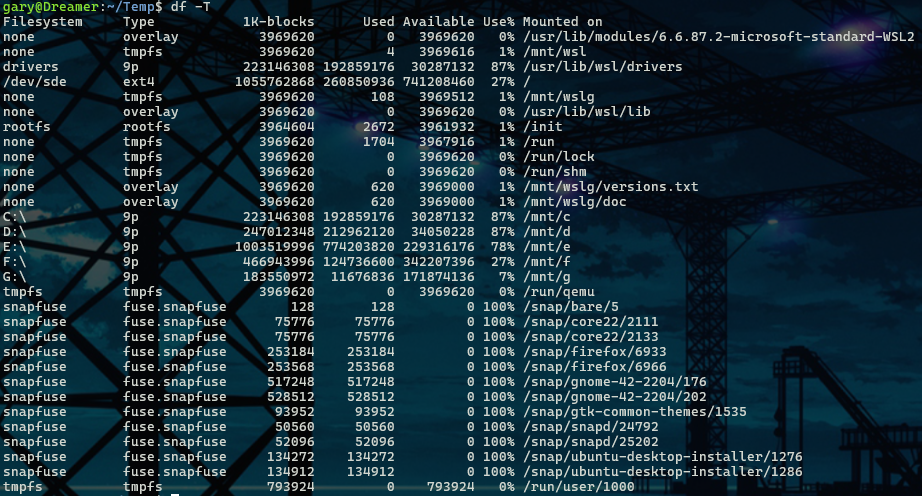
在这里面我们可以找到/根目录,其Filesystem是/dev/sde,Type是ext4
我们这次要实验的内容是上次wmctf的一个rar附件,没打出来真难受
ll wmeasyker.rar
可以发现它的大小为 $16505420 \approx 15 \times 1024 \times 1024$ ,大小大约为15MB符合我们的实验要求
df -T wmeasyker.rar
确认该文件在/dev/sde下
查看文件的物理块映射(簇链)
sudo filefrag -v wmeasykey.rar
- 第一行列出的就是
Filesystem type,其值为ef53,这是ext2/3/4的魔数 - 第二行是该文件的大小和占据的磁盘块数,一块为
4096 bytes - 下面的表格显示的就是该文件的簇链信息,共有两个
extents- 第一个
extnet从逻辑块0~2047,物理块为170856448~170858495,共2048块 - 第二个
extent从逻辑块2048~4029,物理块为69863424~69865405,共1982块 - 其中第二个
extent中记录了上一个extent的结束位置和eof标识符
- 第一个
sudo debugfs "stat /home/gary/Temp/wmeasyker.rar" /dev/sde使用这个命令能看到更详细的信息
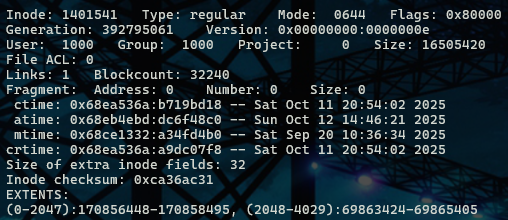
尝试从磁盘中恢复这个文件
首先我们要确定系统的磁盘每一块的大小
sudo tune2fs -l /dev/sde | grep 'Block size'
发现每一块的大小为4096,那么我们就可以使用dd命令从磁盘中读取数据了
# 读取文件
sudo dd if=/dev/sde of=part1.bin bs=4096 skip=170856448 count=2048
sudo dd if=/dev/sde of=part2.bin bs=4096 skip=69863424 count=1982
# 合并文件
cat part1.bin part2.bin > recover_file.bin
truncate -s 16505420 recover_file.bin
得到大小一样的文件,然后我们来检查文件内容是否一致
md5sum recover_file.bin wmeasyker.rar
bingo~
windows下的查找方式
windows下的磁盘一般都是NTFS格式的
winhex直接找到簇号

还是这个文件,先将我们的磁盘在winhex中打开,找到我们的文件,即可找到其簇号的信息,而且我们知道它在根目录下(用作后续的验证)
从 Boot sector 找到 MFT
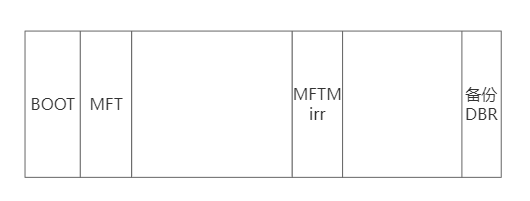
一个NTFS磁盘一般是这样子的,因此我们找到磁盘的最开始就能看到Boot sector
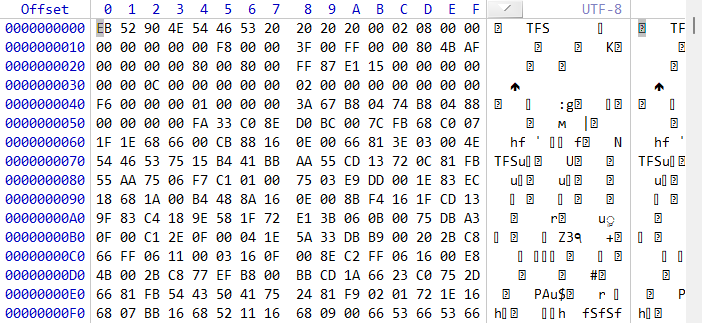
直接放出前0x100偏移的数据,想看更直观的数据可以使用模板自动解析
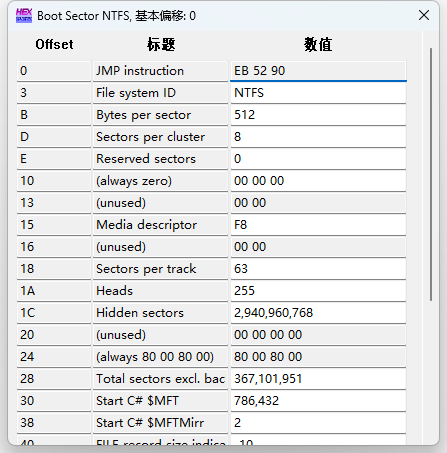
我们还是分析一遍好
我们的目标是找到MFT的位置,那么就需要这么几个关键的数据:
| 参数 | 偏移 | 含义 | 示例值 |
|---|---|---|---|
| Bytes per sector | 0x0B | 每扇区字节数 | 512 |
| Sector per cluster | 0x0D | 每簇扇区数 | 8 |
| Start C# $MFT | 0x30 | $MFT 起始簇号 | 786,432 |
| FILE record size indicator | 0x40 | 每个 MFT 记录大小 | -10 |
计算出每簇的字节数:
ClusterSize = BytesPerSector × SectorsPerCluster
= 512 × 8 = 4096 bytes计算$MFT的起始物理偏移:
MFT_Offset = MFT_Start_Cluster × ClusterSize
786432 × 4096 = 3221225472 (= 0xC0000000)跳转之后发现了这样的内容
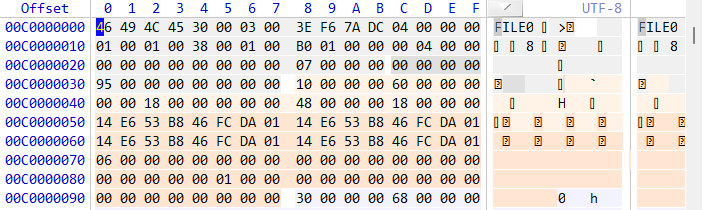
可以发现右侧有FILE0字样,这就是我们要找的$MFT的起始位置了。后来在复盘的时候发现起始可以不用算,Start C# $MFT就是我们要找的值
查看MFT的文件数据区域
在MFT的格式中,数据区域的开头是0x80,那么我们顺着看就能看到了

观察其第 8 位的数据是1代表非常驻属性,在非常驻属性结构中,0x20-0x21是data runs的偏移,其值为0x40,那么在0x40偏移处的值就是data runs,在这里只有一个data runs,该值是32 00 63 00 00 0C,末尾的00 00是结束符,这也代表我们的MFT是一个连续的区域,不是分散的,如果是分散的就要到对应的地方去找
接着来分析data runs,第一位32是压缩字节,高位和低位相加3+2=5,这表示该data runs占 5 个字节,即00 63 00 00 0C
其中高位表示起始簇号占用的字节数,低位表示大小占用的字节数。在这里起始簇号为00 00 0C也就是0xC0000,总共有00 63即0x6300个簇,这和我们先前找到的MFT起始区域是一致的,也就是代表我们的MFT区域从0xC0000簇开始,总共有0x6300个簇

跳转之后到了这个地方,观察右边的详细信息和这个是对的上的
查找根目录的MFT表项
我们继续找到根目录的偏移,在MFT中,根目录是第五个索引号,从我们先前获取的信息可以得知 1 个簇等于 8 个扇区,1 个扇区为 512 bytes,在MFT中获取的FILE record size indicator的值为-10,代表每个MFT项占$2^{-1 \times -10}=2^{10}=1024 \quad bytes$,也就是每 2 个扇区 1 个MFT项,根据这些信息我们就能找到根目录的位置了,计算公式如下:
root_record_offset = MFT_base_offset + 5 * MFT_record_size
0xC0000 = 786432(cluster) -> 786432 * 8 = 6291456(sector)
6291456(sector) + 5 * 2(sector) = 6291466(sector) -> root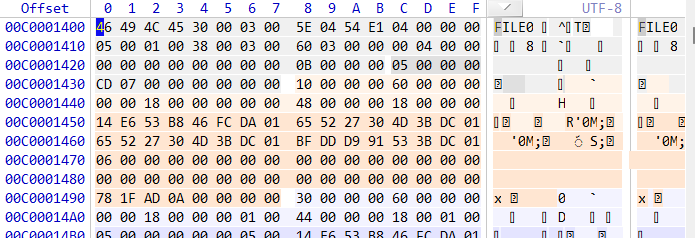
跳转之后是这样的内容,根据右侧的内容可以确定我们找对了
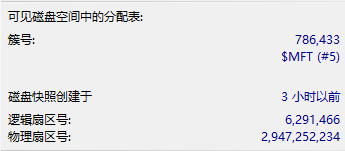
那么接下来就是找root的索引树分配树节点或者索引根属性,对应的header是0xA0和0x90,一般先用0x90,当存储不下时用0xA0,部分目录,会将子节点保存在0x90属性中 ,如只有一个空文件夹的目录结构,或者只有一个文件的目录。其他数据目录结构多在0xA0属性中

我们直接看0xA0的数据
对于一个标准索引头的定义如下:
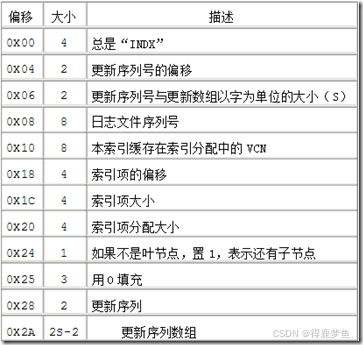
但是在0xA0的索引列表中存在无文件名,无MFT RECORD ID的数据的异常数据,也包括当前节点的索引数据。获取数据的时候需要进行(去噪)处理
最后的结果我们可以在模板中看到
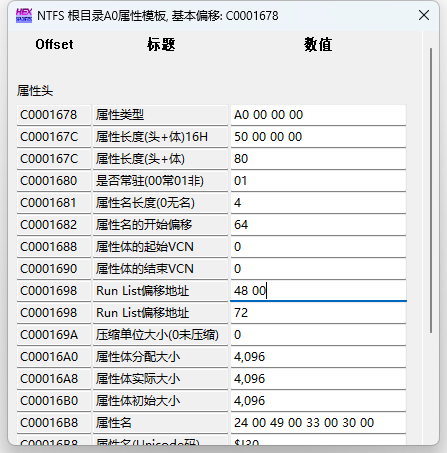
我们所关注的是Run List的偏移地址为0x48

这是对应的数据,那么直接计算就行0x24起始,大小0x1
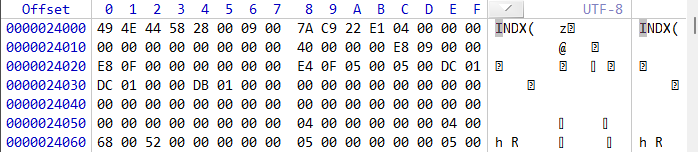
跳转之后在这个地方,观察右侧数据显示正确

那么我们接着找根目录下的文件就行
找到目标文件
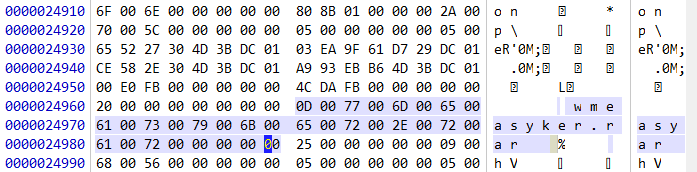
在这里就找到了我们的文件名,根据下图计算出文件MFT的索引号
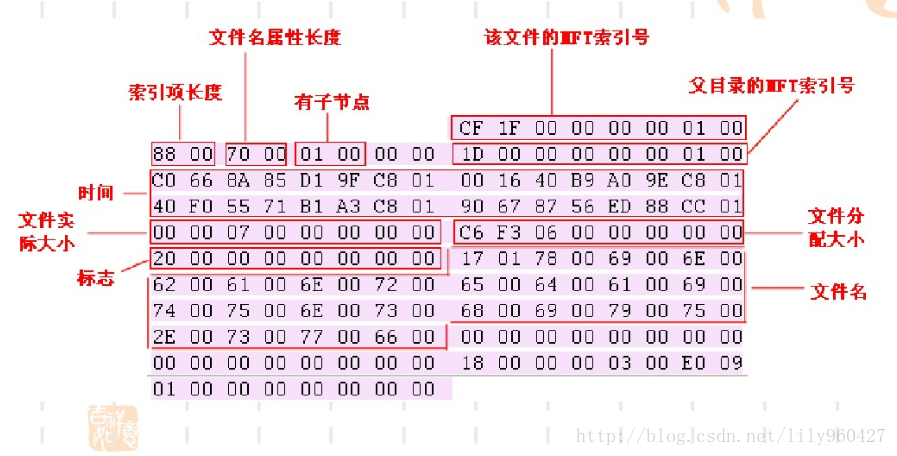
我们直接上模板就行,就是个一一对应
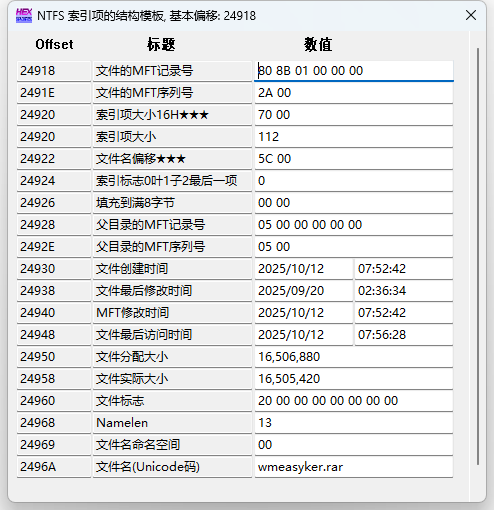
其中有用的是文件的MFT记录号
0x18B80 = 101248(index) / 4 = 25312(cluster)
786432(MFT cluster) + 25312(cluster) = 811744(cluster)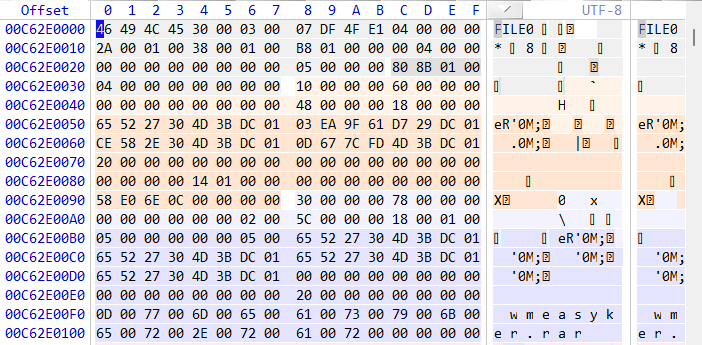
跳转后发现正式我们要找的文件的MFT,然后找它的data runs就行了
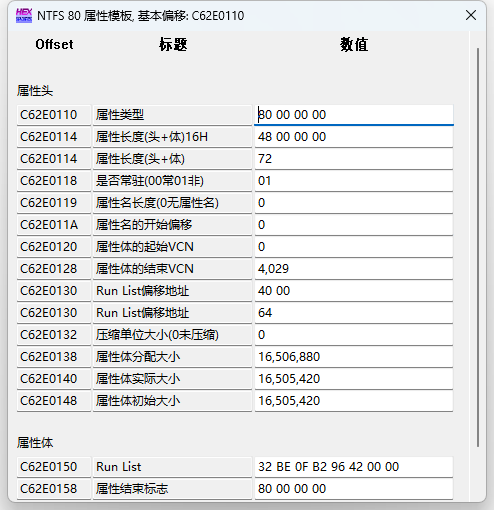
Run List的值为32 BE 0F B2 96 42 00 00
将其分割就是B2 96 42(0x4296B2)和BE 0F(0xFBE)
找起始簇4363954,跳转!
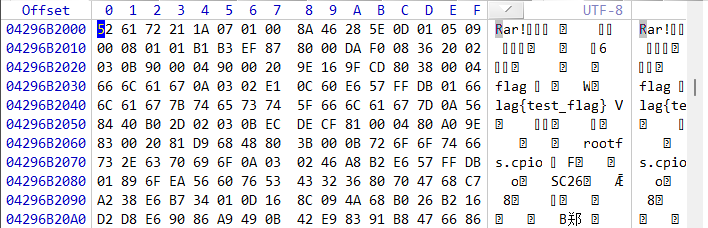
跳转后发现正确的文件头同时在右侧找到对应的信息

和一开始根据文件名找到的信息对上了,都 5 小时前了,成功了!!!:)
如果还有子文件夹,那么递归查找就行,重复工作
总结
这次实验研究了Linux和Windows两种操作系统下两种文件系统ext4和NTFS的磁盘存储,其中Linux下的相对简单,Windows下的则较为复杂,还是要多实践才能搞懂其中的原理 🙂


质量很高